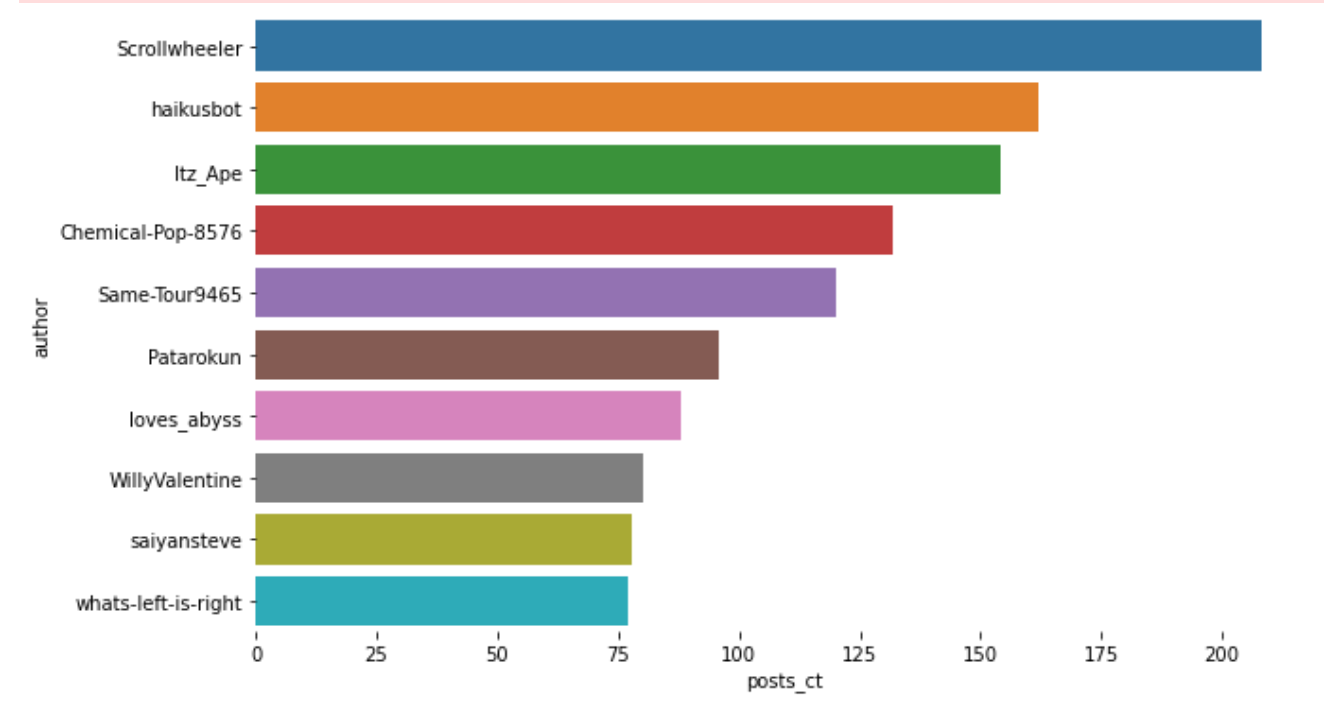
In the NLP part, pipelines for data cleaning, keyword extraction, and sentiment analysis are designed to further showcase sub-datasets. First, I convert text to tokens, remove punctuation, stop words, perform stemming using Spark NLP's annotators. Then, counting the words and using TF-IDF to find important topic, pass and utilize their subject or more keywords. Finally, building the sentimenthe sentiment of the comment and identified as "negative", "positive" or "neutral".
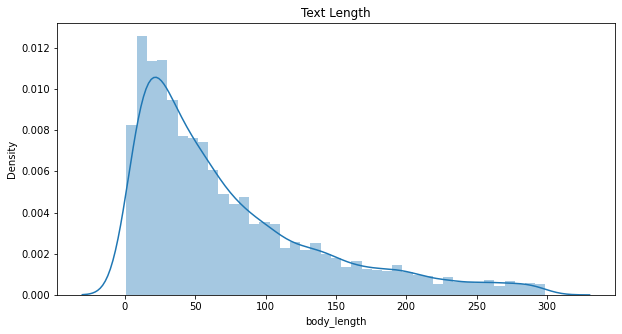
The contexts are represented by varible body, describing length of body:
After histogram the len_body data, filtering text length less that 300 which still can represent majoriaty of text to get the text length histogram plot.
The text length are usually less that 25 words.
Before cleaning data, roughly counting the words. The top 20 words are shown as below:

Most words are meaningless, that's why we need clean the text data.
Here we use pipline to Convert text to tokens, remove punctuation, stop words, perform stemming using Spark NLP's annotators.The each parts results are shown as below:
 |
 |
 |
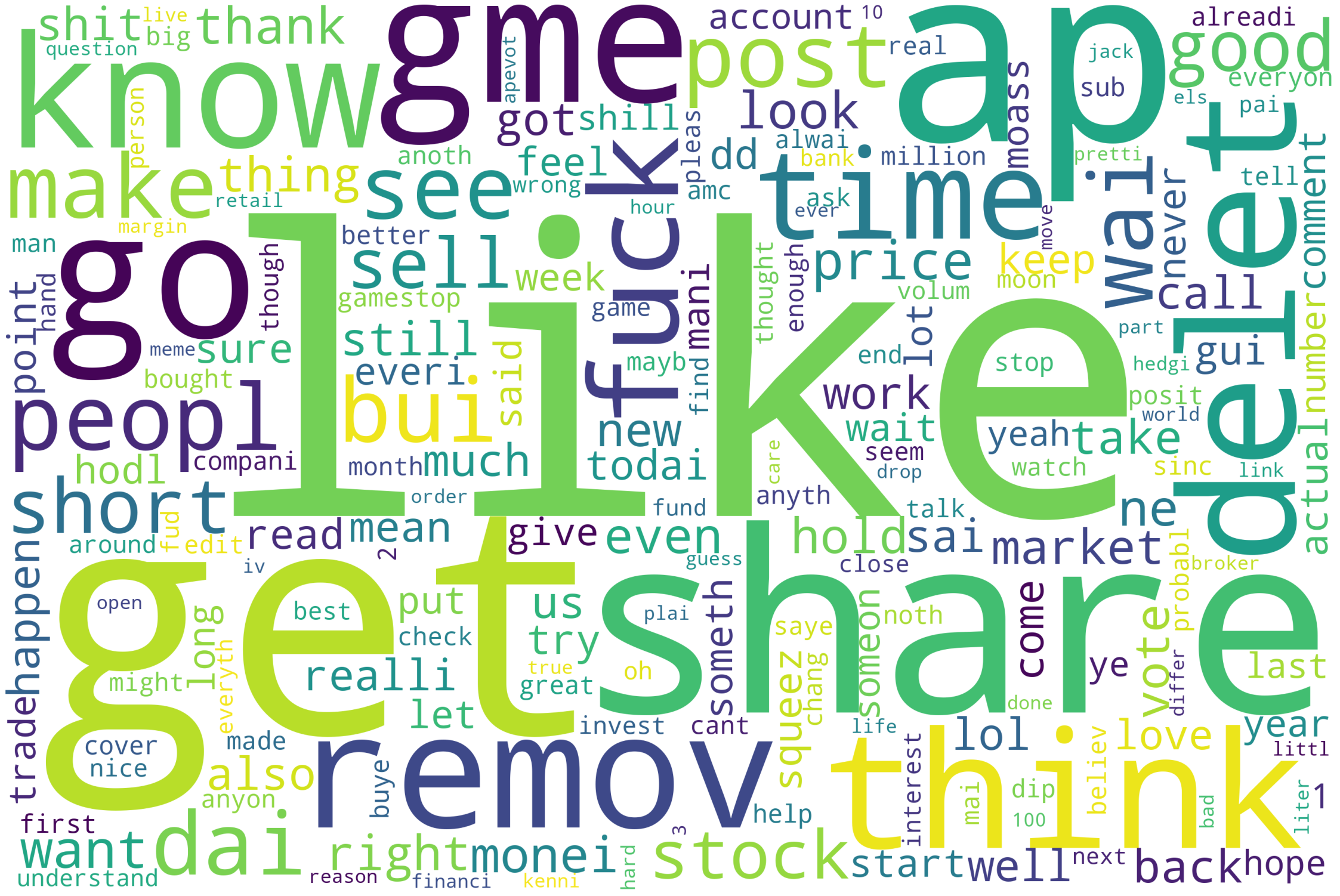
Now, let's try to find the import topic. First, let's see the wordcloud of most common words.(See in left)
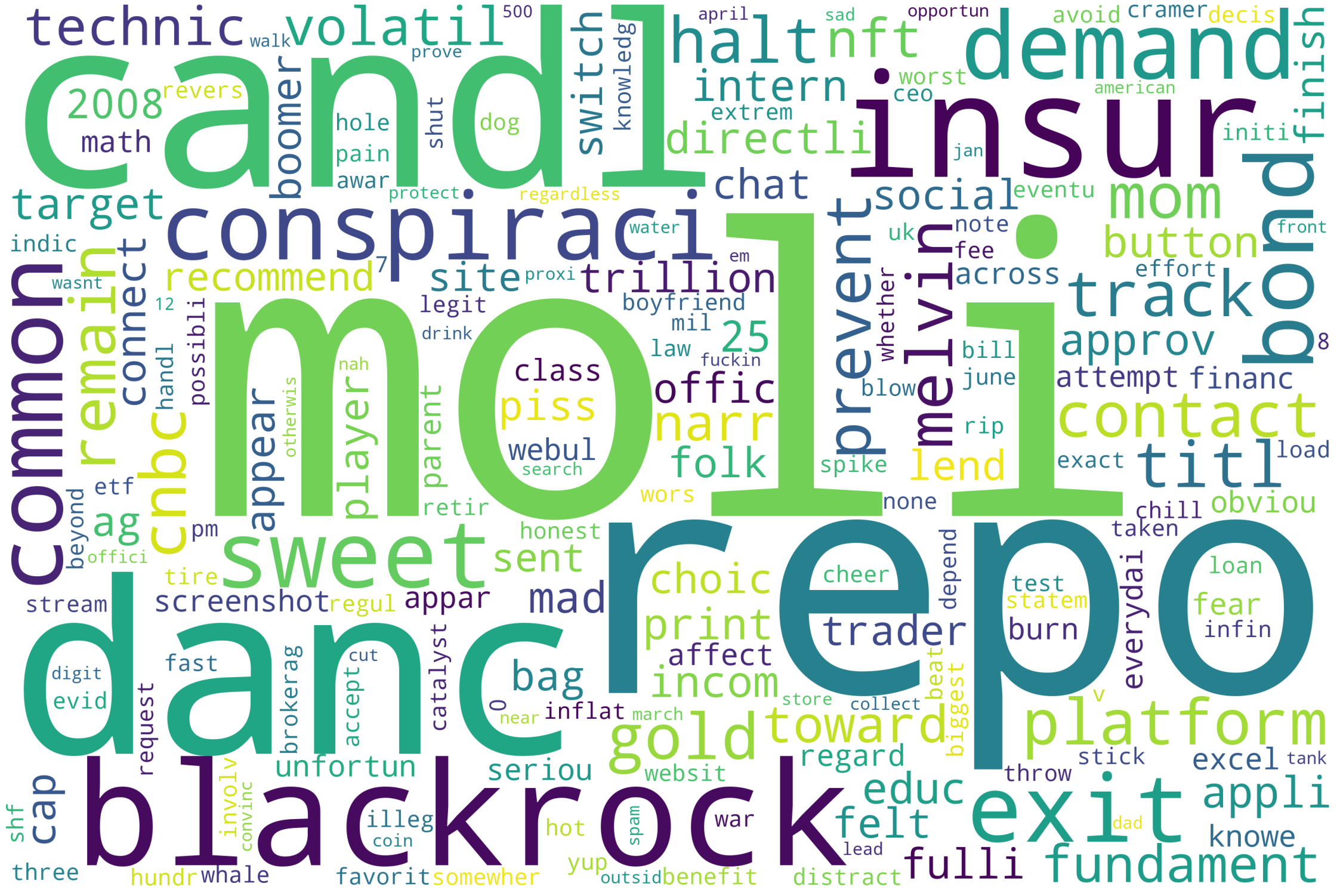
Then, let calculate the TF-IDF, and see the wordcloud of most important words. (See in right)
 |
 |
In the most common words cloud on the left, "like" is the word that appears the most, which may indicate that the overall forum comment sentiment is more positive, which we will explore in the next work. At the same time, the word "share" also has a high ranking. It is worth noting that "gme" and "share" here represent more noun meanings, which is not difficult to accept--many users in the Superstonk community are GME shareholders. At some point, they may have heated discussions about what to do with GME stock as the price of GME stock fluctuates wildly.
In the most common word cloud on the right, "moli" should actually be "moly" which is the word with the highest weight. "moly" is often used as a combination in "Holy moly". According to the TF-IDF calculation rules, the words that appear multiple times below appear higher, so "moly" becomes the word with the highest weight. Another word worth noting is "blackrock," which refers to Blackrock Fund Advisors, one of the companies with the most shares of Gamestop.
Also, build the topic model, here is the result:
Unfortunatly, the result of topic model isn't as meaningful as wordclouds.
Base on previouse results, three dummy variables are created.
Using pipline the build sentiment model for comments. The identifiers are "positive" "Negative" "Neutral".The part of results are shown as below:
The distribution of each sentiment comments counting are show as below:
The positive comment are the most which prove the previous guess. At the same time, it is worth noting that among the replies, the proportion of posts with positive sentiments is higher, indicating that positive posts are more popular in this community.
The following is the sentiment distribution according to the four dummy variables. It is found that the posts with neutral sentiments account for the highest proportion in the category of Popular_commented. At the same time, under the flair "voted", the proportion of positive posts is the highest.
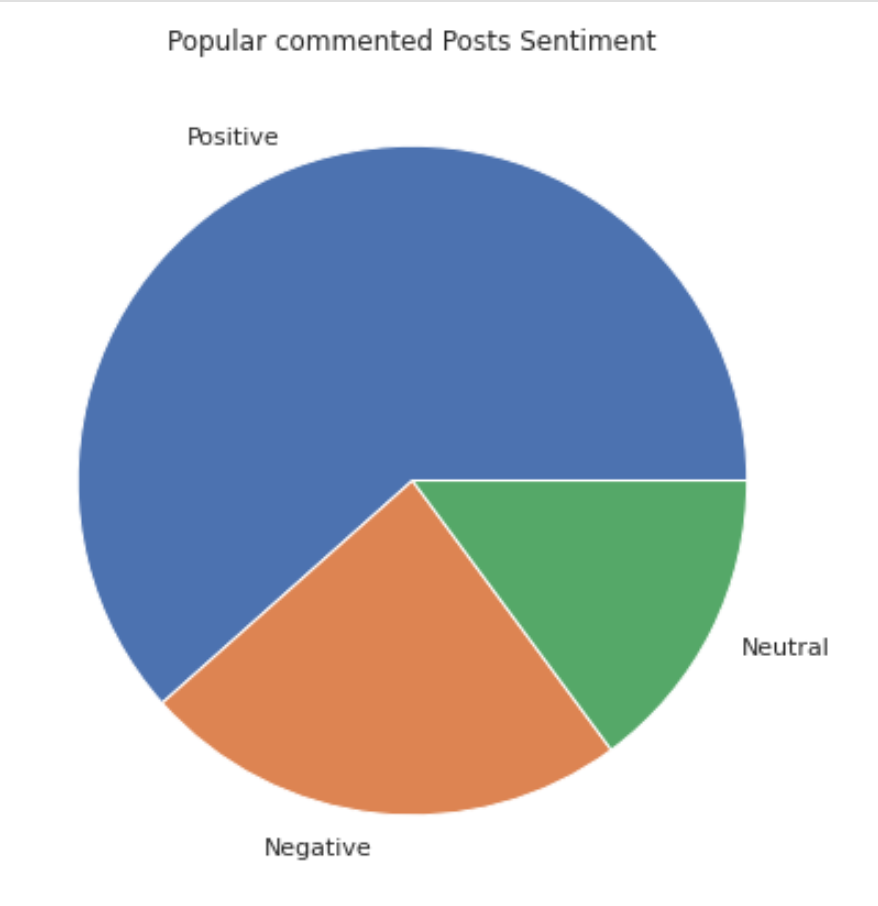 |
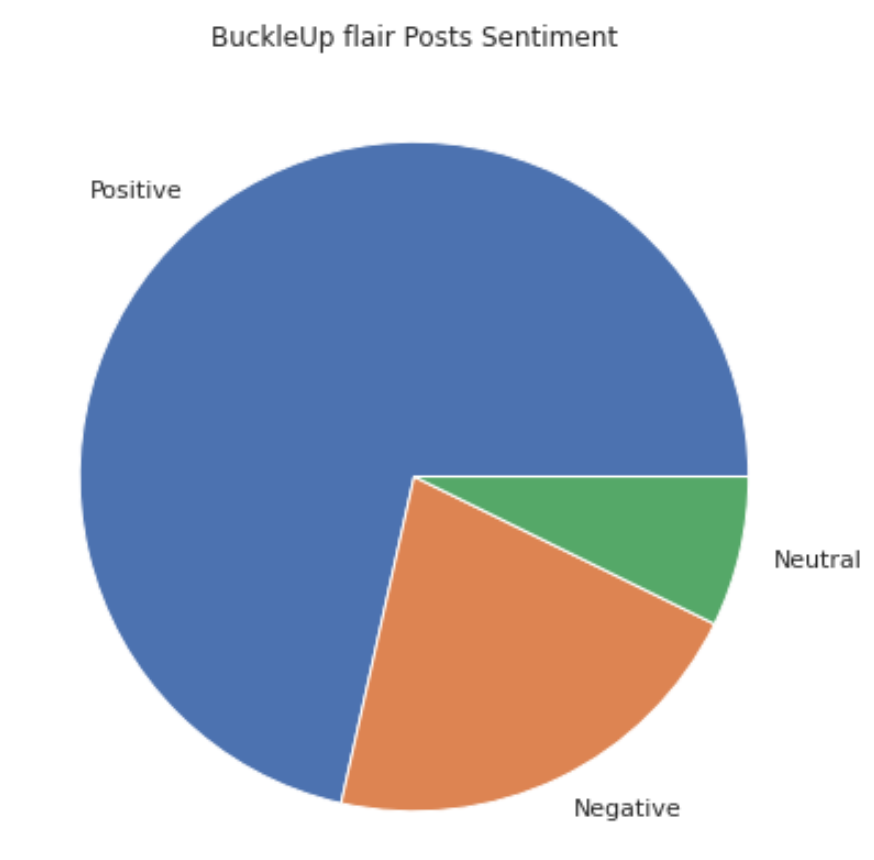 |
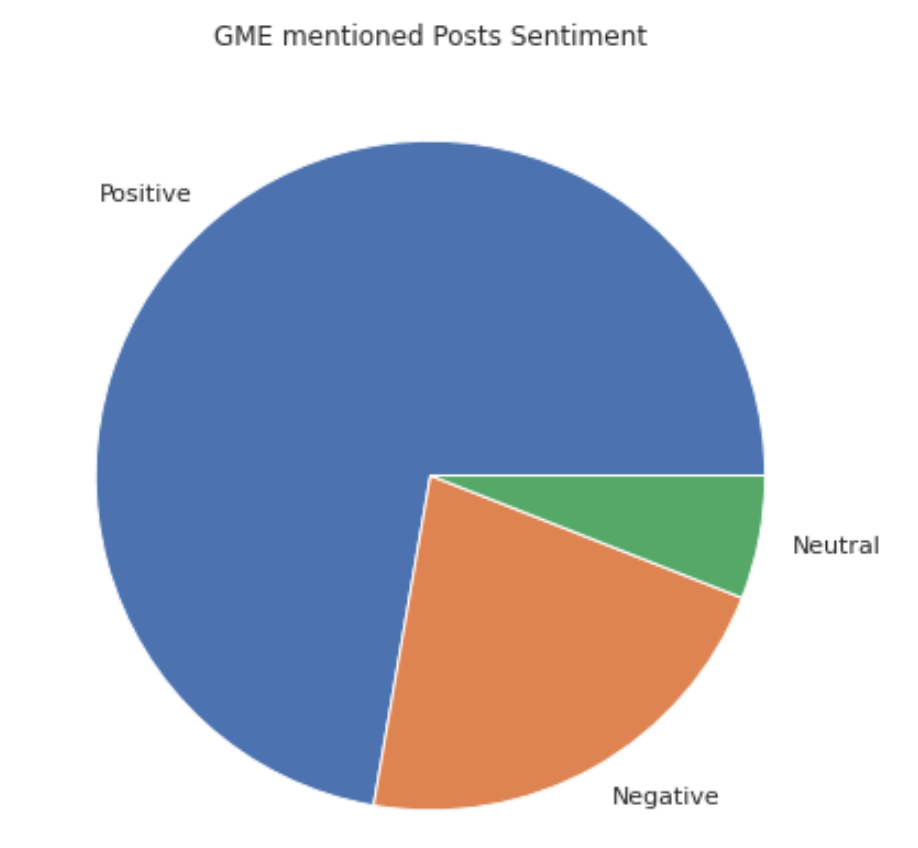 |
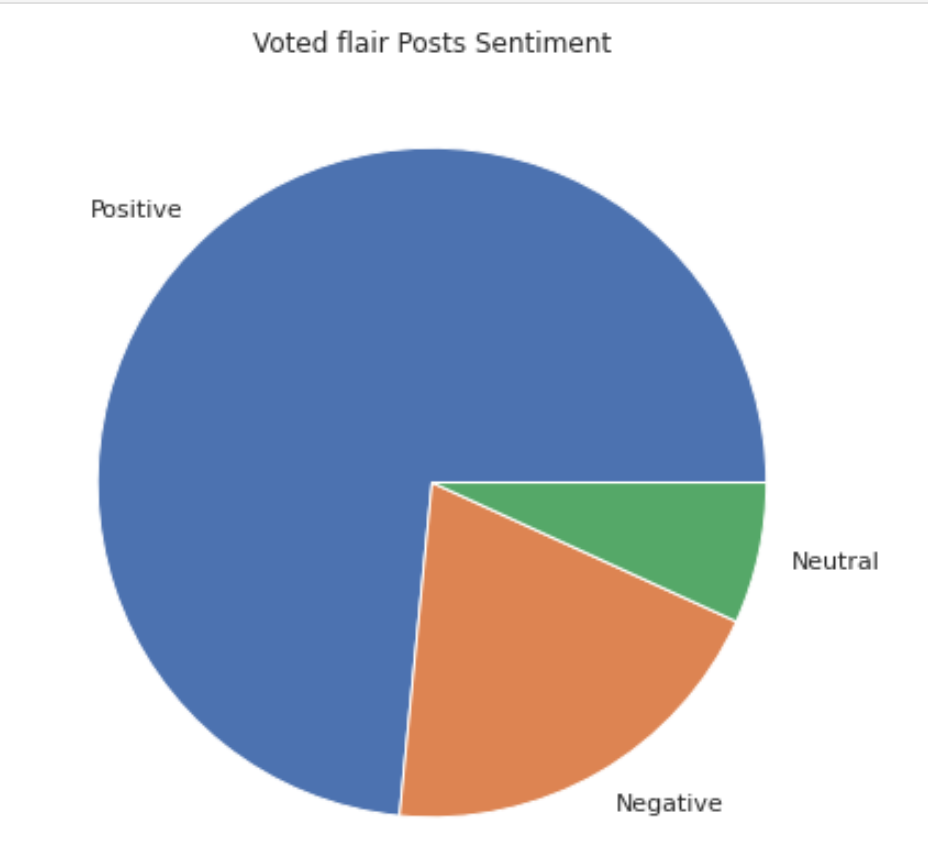 |
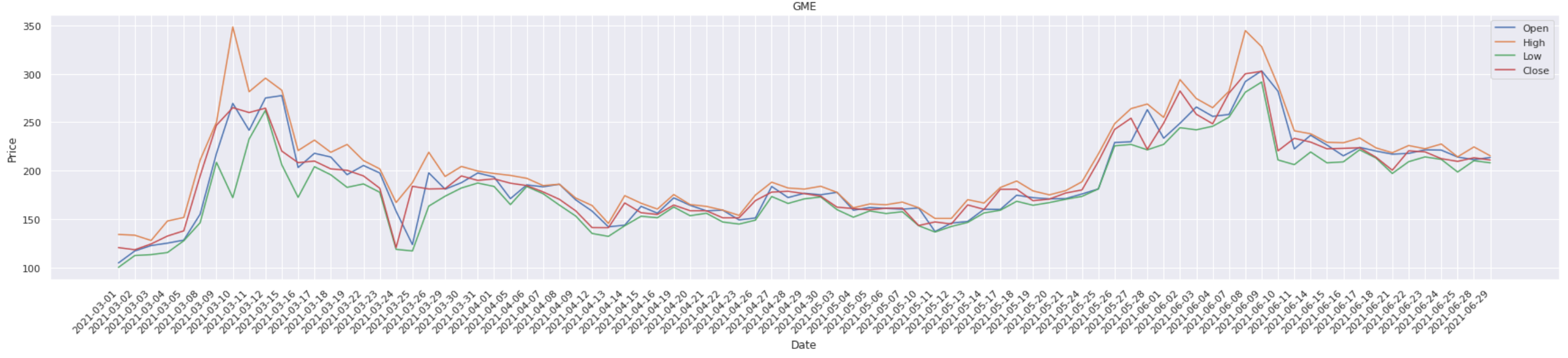
Meanwhile, the flow of sentiment over time is shown in the figure below.
The overall sentiment of the forum has been positive, if we just look at the gap between positive and negative, recall that June 9th was the highest day for gme stock price, the gap between positive and negative was the largest on that day, and mid-to-late April When the gme is relatively low, we can see that the gap is relatively small.