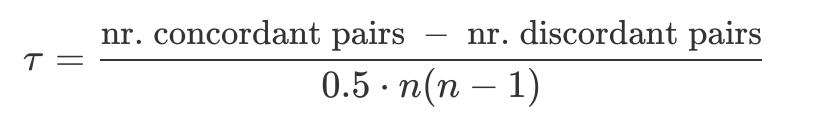
In the ML part, dataset uesd are from NLP project result. Two business goal is settled: Predict the posts will be a popular commented posts and Predict the sentiment of the posts. The pipelines used for convert string features and label. The metric "Acuracy", "Recall","Precision", "MSE", "ROC", "F1" are used for model valuing. For each classifier, modify the hyperprameters for better perfomance.
'author_created_time' and 'created_time' which were given in Unix time mili-seconds to readable time.is_popular_commented :1 means that the number of posts with the same "parent_id" is greater than 3*;otherwise, it is 0. (*This number comes from the number of posts with the same (*this number comes from the analysis of posts with the same "parent_id")is_weekend : A value of 1 means the post was generated on a weekend day;otherwise, it is 0.is_PtoP : A value of 1 means the post belongs to the "🎮 Power to the Players 🛑 ", which is the top 1 flair.is_BuckleUp: A value of 1 means the post belongs to the "🦍 Buckle Up 🚀 ", which is the top 2 flair.is_voted: A value of 1 means the post belongs to the "🦍Voted✅", which is the top 3 flair.author_age : The number of days between the creation date of the author's account and the date of the posting. author_postcnt : Total number of posts by authorTo get some insight in how each of the features would influence our classification task, we look at the Kendall rank correlation coefficient. This is a correlation measure for the ordinal association between two variables. It is evaluated with the formula:
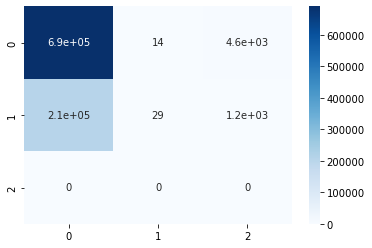
where n is the total number of observations. The following heatmap displays the correlations between the pairs of features in the dataset:

There are two types of values we are looking for:
For task 1 where LABEL = "no_followed" , the columns "blackrock_mentioned", "send_replies", "gme_mentioned", "share_mentioned", "blackrock_mentioned", "stickied" are droped due to weak relationship.
The goal is to predict the popularity of the post. Posts that are followed are usually considered to be popular posts.The column "no_followed" are used as label.
After data cleaning, 5,471,500 rows of data were remained. Spliting them into three datasets, where 4,376,331 data are used as the training set, 986,010 rows of data are used as the test set, and 109,159 rows of data are used as the prediction set.
This is a Supervised Machine Learning problem since we are working with labelled data, and also a binary classification problem as each post will be categorized as followed or no_followed. The approach is offline since the data is static, it was collected over a period of several months and it does not receive new records.
The classifiers for this task used are: Linear Support Vector Machine (LSVC) and Gradient Boosted Trees (GBT).
The metrics "Accuracy", "Recall", "Precision", "F1" and "AUC" are better way for task 1 since data is imbalanced with respect to followed and no_followed. The summary table of models are showed as below:
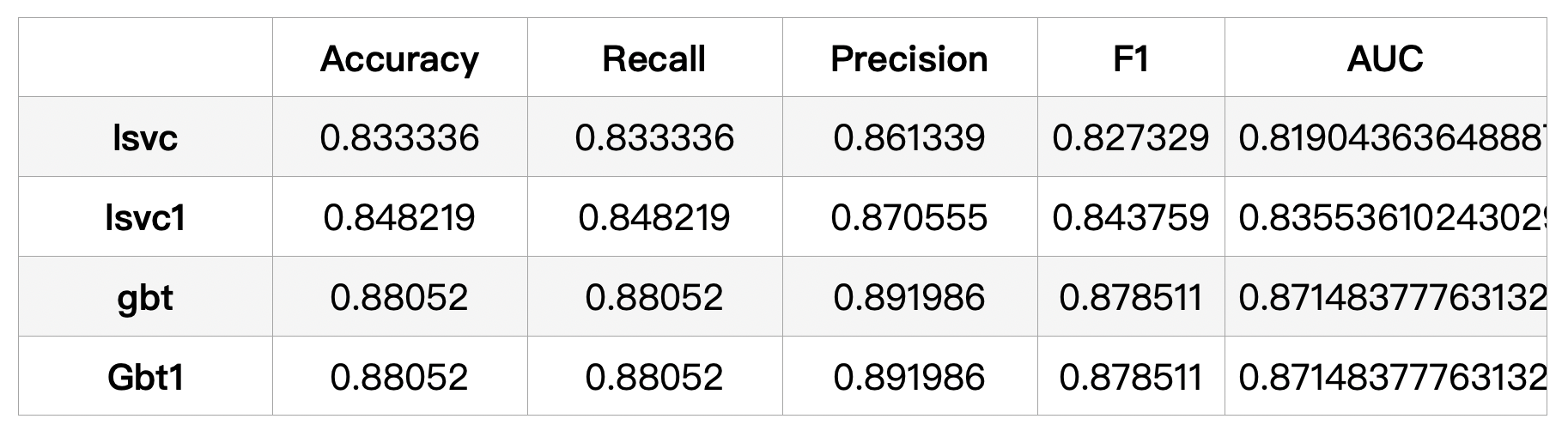
The tuning for GBT is changing maxDepth from 5 to 20, maxBins from 32 to 128, stepSize from 0.1 to 0.5. However, the impact of these changes on the evaluation metrics was not significant, but this did not detract from the fact that GBT was the best model for Task 1 among all evaluation metrics.
Since the number of features (13) is relatively large, the tuning for LSVC is increasing aggregationDepth into 5, which improve the performance of GBT model.
It is worth noting that "sentiment" was not included as a feature in the initial model building, and the overall performance of both models was not as good as it is now. This suggests that the sentiment of a post has an impact on whether or not the post will receive a response, a conclusion that is also shown in the NLP section.
A look at the confusion matrix confirms that the GBT model is a good predictor of whether a post will receive a response with a high precision score.
As it mentioned in task 1, the sentiment is an influencing factor in the popularity of a post. It is a necessity to continue the sentiment analysis of the post.
In task 2, external data set GameStop Stock price(GME) will be used as FEATURE to help build a predictor for post sentiment classification.
Weekend post data is filtered due to the missing time of the stock during the weekend. In the end, 4,170,801 rows of data were remained, where 3,336,530 data are used as the training set, 751,268 data are used as the test set, and 83,003 data are used as the prediction set. The column "sentiment" are used as label.
The label variable for this task isn't binary, two feature transformer and a label convertor are combined in pipleline:
StringIndexer : encodes the sentiment variableOneHotEncoder IndexToString : decodes the prediction index back to sentiment stringThe classifiers for this task used are: Random Forest (RF) and Multilayer Perceptron Classifier (MLPC).
As an effort to improve the performance of the model, the weight of the sentiment is calculated as the variable "weight_sen" and is used as a hyperparameter of the model.
The metrics "Accuracy", "Recall", "Precision", "F1", "MSE", "Var" and "AUC" are used. The summary table of models are showed as below:
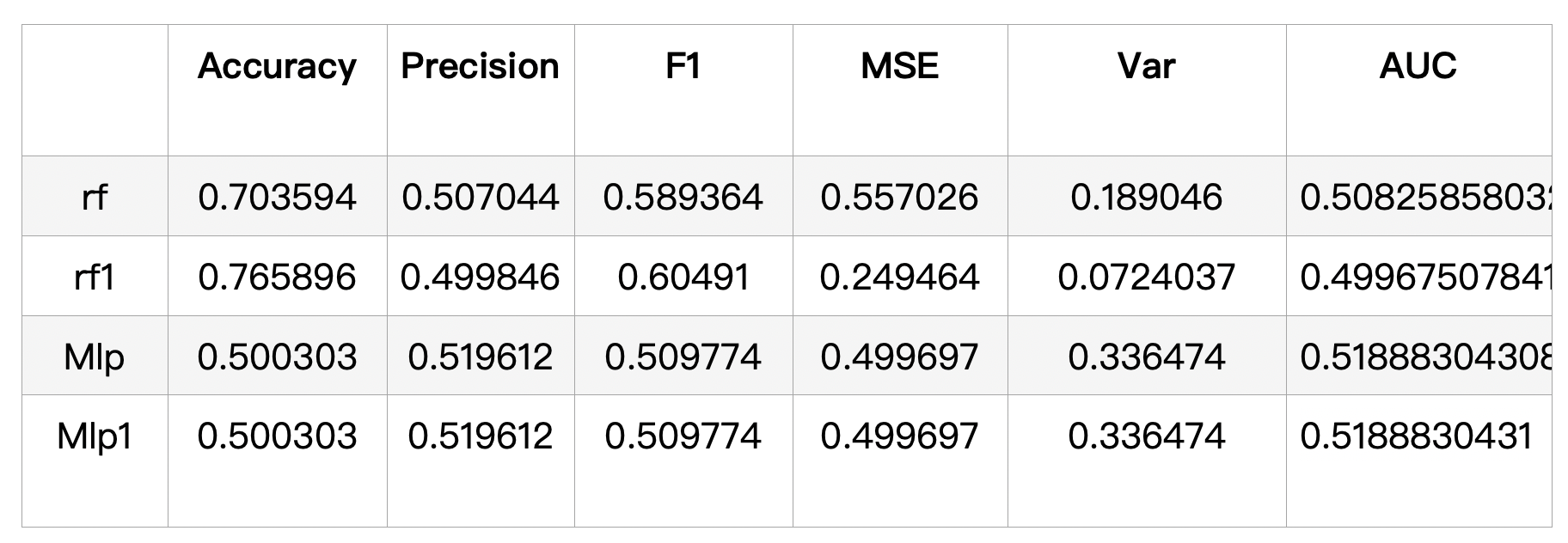
We can see from this table, that the overall scores of the RF model are better than of the MLP model. However, the MLP model has higher precision score.
This result is not unexpected -- as random forests are generally acknowledged to give good results in most cases especially with large amounts of data. In the process of tuning the random forest, it was found that adding numTree and maxDepth improved the model significantly.
The base line MLPC we work with that has layers with [11, 2, 2]. The input layer contains 11 nodes (same as the number of predicting features) and the output layer has 2 nodes since we are dealing with binary classification. There is a hidden layers with 2 nodes. With the modifacation of maxIter, blockSize and stepSize, the perfomance of model looks like little change. But an funding is that with the lager maxIter and blockSize, the trained time is significantly increasing.
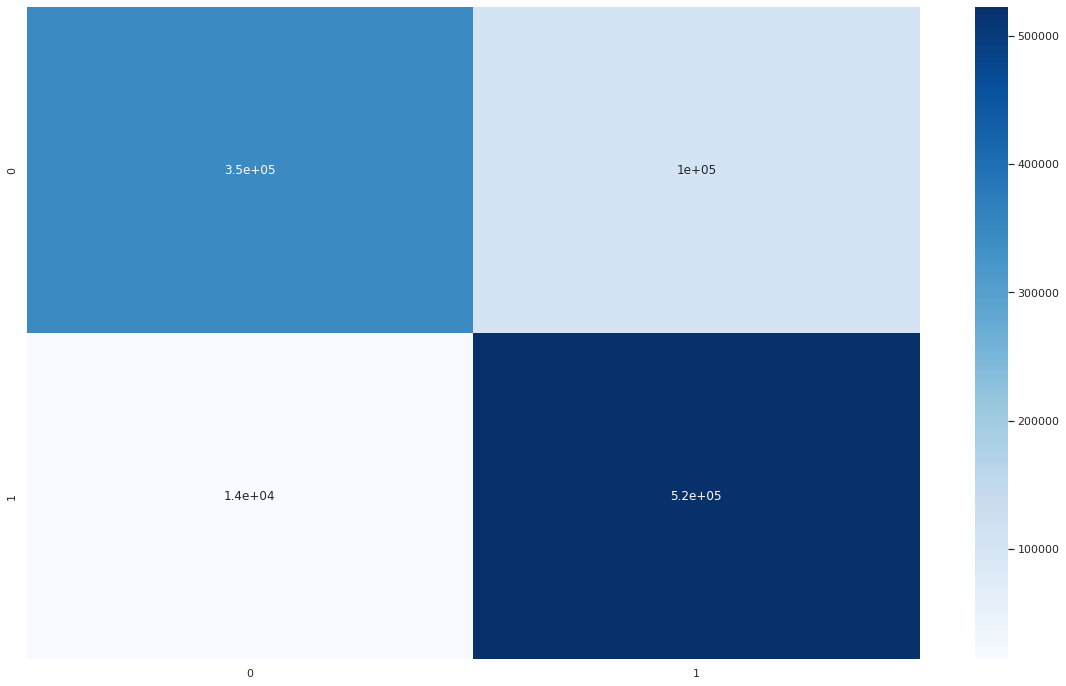
And the confusion_matrix of best RF is showed as below. The model a pretty high FF, which shows the model is not accurate enough to predict negative posts, and more work needs to be done in the future.